Environnement de développement
Vous devrez configurer un environnement dans lequel vous pourrez développer en utilisant CUDA C.
Les prérequis pour développer du code en CUDA C sont les suivants:
1-1. CUDA-ENABLED Processeurs graphiques (GRAPHICS PROCESSORS)
Heureusement, il devrait être facile de trouver un processeur graphique construit sur l'architecture CUDA, car chaque GPU NVIDIA depuis la version 2006 de la GeForce 8800 GTX est compatible CUDA.
Pour une liste complète, vous devriez consulter le site Web de NVIDIA www .nvidia.com/cuda,
tous les GPU récents (GPU à partir de 2007) avec plus de 256 Mo de mémoire graphique peuvent être utilisés pour développer et exécuter du code écrit avec CUDA C.
1-2. Pilote De Périphérique NVIDIA (Device driver)
NVIDIA fournit un logiciel système qui permet à vos programmes de communiquer avec le matériel compatible CUDA.
1-3. Kit D'outils De Développement CUDA (CUDA Development Toolkit)
Si vous disposez d'un GPU compatible CUDA et du pilote de périphérique NVIDIA, vous êtes prêt à exécuter le code CUDA C compilé.
Les applications CUDA C vont être exécutées sur deux processeurs différents, vous aurez donc besoin de deux compilateurs.
Un compilateur compilera le code pour votre GPU et un autre compilera le code pour votre CPU.
NVIDIA fournit le compilateur pour votre code GPU : vous pouvez télécharger le Kit D'outils De Développement CUDA sur http://developer.nvidia.com/object/gpucomputing.html.
Pour le compilateur du code CPU le choix est selon le système d’exploitation. Windows : Microsoft Visual Studio C. Linux : gcc.
Un premier exemple

On utilisera le mot Host pour désigner le CPU et sa mémoire et le mot Device pour désigner le GPU et sa mémoire.
Dans cet exemple on remarque qu’il n'y a pas de différence entre CUDAC et standard C dans la mesure où l’exécution est sur le host c.a.d le CPU.
2-1. La fonction Kernel

Nous voyons maintenant que CUDA C ajoute le qualificatif __global__ au standard C.
Ce mécanisme avertit le compilateur qu'une fonction doit être compilée pour s'exécuter sur le device au lieu de host.
Dans cet exemple simple, nvcc donne la fonction kernel() au compilateur qui gère le code du device, et il transmet main() au compilateur host comme il l'a fait dans l'exemple précédent.
L'astuce consiste en fait à appeler le code du device à partir du code du host. Les crochets (<<< …>>>) désignent les arguments que nous prévoyons de transmettre au runtime.
Ces arguments ne sont pas pour le code du device , mais des paramètres qui influenceront la façon dont le runtime lancera ce code.
Les arguments du code du device sont transmis entre parenthèses, comme tout autre appel de fonction.
2-2 Le passage de paramètres
Considérez l'amélioration suivante de notre exemple:

- Les paramètres pour la fonction kernel sont transmis comme nous le ferions avec n'importe quelle fonction C.
- Nous devons allouer de la mémoire pour faire tout ce qui est utile sur un device , comme renvoyer des valeurs à host.
Rq : On ne peut pas utiliser les pointeurs alloués avec cudaMalloc() pour lire ou écrire dans la mémoire à partir du code qui s'exécute sur le host. 2-3.
Interagir avec les Devices-GPUs- Il serait utile que notre programme ait un moyen de connaître la quantité de mémoire et les types de capacités dont dispose le device.
Avant d'entrer dans l'écriture du code des devices, nous aimerions disposer d'un mécanisme permettant de déterminer quels appareils (si plusieurs device) sont présents et quelles sont les capacités de chaque device.
Pour savoir combien de devices :
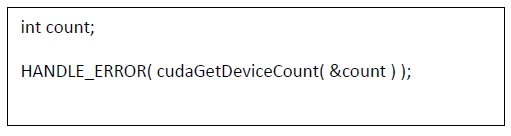
Après avoir appelé cudaGetDeviceCount(), nous pouvons ensuite parcourir les devices et interroger des informations pertinentes sur chacun.
Le runtime CUDA nous renvoie ces propriétés dans une structure de type cudaDeviceProp

2-4. utilisation des propriétés de device
Si on a plusieurs GPUs dans notre système nous voulons choisir le GPU rapide doté du plus grand nombre de multiprocesseurs sur lequel notre code exécutera.
Ou bien choisir celui qui supporte les opérations arithmétiques avec des virgules flottantes double précision.
Après la consultation de l'annexe A du guide de programmation NVIDIA CUDA, nous savons que les cartes dotées d'une capacité de calcul 1.3 ou supérieure prennent en charge les mathématiques à virgule flottante double précision.
Nous devons trouver au moins un device-gpu- doté d'une capacité de calcul 1.3 ou supérieure. Exemple :

L'appel à cudaChooseDevice() renvoie un identifiant de device que nous pouvons ensuite transmettre à cudaSetDevice().
À partir de ce point, toutes les opérations sur le device auront lieu sur le device que nous avons trouvé avec cudaChooseDevice().