Introduction
Le développement de la programmation parallèle a créé le besoin de mesures de performances pour évaluer les performances d'un algorithme parallèle afin de décider si son utilisation est pratique ou non.
Pour analyser cela, quelques indices de performances sont introduits : accélération (speedup) et efficacité (efficiency).
Indices de performances
2.1- Accélération- Speedup
L'accélération est la mesure qui montre l'avantage de résoudre un problème en parallèle.
Il est défini comme le rapport du temps nécessaire du meilleur algorithme séquentiel pour résoudre un problème de taille n sur un seul élément de traitement, Ts(n,1) (i.e., Ts(n,1) ≤ T(n,1)),
au temps nécessaire pour résoudre le même problème sur p éléments de traitement identiques, T(n,P) .
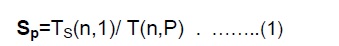
On a les cas suivants : - S = p …. est une accélération linéaire ou idéale -S < p …. c'est une vraie accélération.
Autrement dit, un calcul parallèle sur p processeurs ne peut pas s'exécuter p fois plus vite que le meilleur algorithme séquentiel. -S > p …. est une accélération superlinéaire.
En pratique, il est difficile d’obtenir une accélération linéaire, encore moins une accélération linéaire parfaite, car les goulots d’étranglement de la mémoire et la surcharge (contrôle et communication) augmentent en fonction de p.
La loi d'Amdahl
Soit c la fraction (sous forme a/b ou sous forme de nombre réel) d'un programme parallèle, (1−c) la fraction qui s'exécute de manière séquentielle et p le nombre de processeurs.
La loi d’Amdahl : pour un problème de taille fixe, l’accélération globale attendue est donnée par :
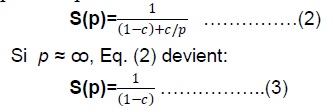
Exemple :
si c=4/5 alors l'accélération maximale est 5x.
Autrement dit, si un ordinateur possède un grand nombre de processeurs (c'est-à-dire un super-ordinateur ou un GPU moderne),
alors l'accélération maximale est limitée par la partie séquentielle de l'algorithme.
La loi de Gustavson
Dans la loi de Gustafson, le temps d’un programme parallèle est composé d’une partie séquentielle s et d’une partie parallèle c exécutées par p processeurs.
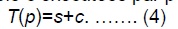
Si le temps séquentiel pour tous les calculs est s+cp, alors l'accélération est :
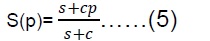
La loi de Gustafson est importante pour élargir les connaissances sur le calcul parallèle et la définition de l’accélération.
2-2. Efficacité(efficiency)
L’efficacité nous indique dans quelle mesure les divers processeurs sont bien utilisés ou pas.
L’efficacité d’un programme est le rapport entre le temps d’exécution séquentiel et le coût d’exécution sur une machine à p processeurs :
L’efficacité d’un programme est le rapport entre le temps d’exécution séquentielle et le coût d’exécution sur une machine à p processeurs :
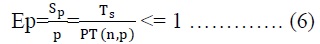
- Ep=1 est l'efficacité maximale et signifie une utilisation optimale des ressources de calcul.
- Une efficacité maximale est difficile à atteindre (c'est une conséquence de la difficulté d'obtenir une accélération linéaire parfaite).
2-3. FLOPS
- La métrique FLOPS représente les performances arithmétiques, est mesurée en nombre d'opérations en virgule flottante par seconde.
Soit Fh la performance maximale en virgule flottante d'un matériel connu et Fe la performance en virgule flottante mesurée pour une implémentation d'un algorithme donné, alors Fc est défini comme :
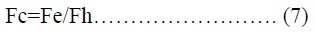
- Fc nous indique l'efficacité du calcul numérique par rapport à un matériel donné.
- Une valeur Fc=1 signifie une utilisation maximale du matériel pour les calculs numériques.
- Depuis juin 2022 le supercalculateur le plus puissant du TOP500, atteignant 1102 pétaFlops (1 102 exaFlops.
- Les CPU haut de gamme offrent jusqu'à 240 GFlops (Intel Xeon E5 2690) de performances numériques tandis que les GPU haut de gamme proposent
environ 4 TFlops (Nvidia Tesla K20X), équivalent à un super-ordinateur il y a dix ans. En raison de cette grande différence d’ordre de grandeur,
les gens de la communauté HPC s’orientent vers le calcul GPU.
2-4. Performance par Watt
Ces dernières années, la consommation d’énergie est devenue plus importante que l’accélération.
Aujourd'hui la notion de performance par watt est l'une des mesures les plus importantes dans le choix du matériel et a fait l'objet de recherches.
- développer du matériel économe en énergie est devenu un moyen de réaliser du HPC de manière responsable.
- Le supercalculateur Titan fonctionne au prix de 8,2 MW, offrant 2,1 GFlops/W, tandis qu'un GPU Nvidia Tesla K20X offre 16,8 GFlops/W en utilisant 300 W.
- L'intégration des GPU dans les supercalculateurs a aidé ces derniers systèmes pour être plus économes en énergie qu’auparavant.
2-5 Bande passante mémoire (Memory Bandwidth)
La bande passante mémoire est la vitesse à laquelle les données peuvent être transférées entre les processeurs et la mémoire principale.
Il est généralement mesuré en Go/s.
L'efficacité mémoire Bc d'une implémentation est calculée en divisant la bande passante expérimentale Be par la bande passante maximale Bh du matériel :
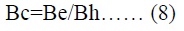
- Une valeur Bc=1 signifie que l'application utilise la bande passante mémoire maximale disponible sur le matériel.
- Les processeurs haut de gamme actuels ont une bande passante mémoire comprise entre 40 Go/s ≤ Bh ≤ 80 Go/s, tandis que les GPU haut de gamme ont une bande passante mémoire comprise entre 200 Go/s ≤ Bh ≤ 300 Go/s.