La distribution des données
Ce qui fera la différence entre les types d’architecture sera:
-La manière de distribuer et d’accèder aux données .
-Le nombre et la puissance des unités de calcul, des coeurs.
-La qualité des différentes voies de communication .
Pour paralléliser il faut classer les architectures en fonction de ces critères :
1-Le traitement du flot d’instructions : le processeur peut-il exécuter plusieurs instructions simultanées ? Autorise un parallélisme d’instructions.
2-Le traitement du flot de données. Un parallélisme de données est-il possible ?
3-Le type de mémoire : partagée, distribuée ou hybride.
4-Le type de réseau disponible : comment faire transiter les données, les messages ?
6-1 Les types de mémoire La distribution des données peut être en:
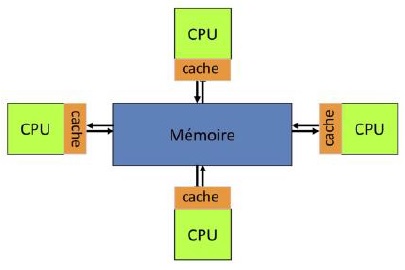
1)Mémoire partagée Un espace mémoire global, accessible simultanément par plusieurs CPUs et donc par plusieurs programmes.
-Tous les CPUs accèdent à toute la mémoire globale, avec un même espace d’adressage.
Chaque CPU est autonome mais les modifications effectuées dans la mémoire partagée sont visibles par tous.
-Les processeurs ont leur propre mémoire locale (cache, …) dans laquelle sera copiée une partie de la mémoire globale.
Avantages
Accès rapides à la mémoire et partage des données
Inconvénients
- Accès concurrents , risque d’embouteillage Cohérence des caches : la diffusion de la modification des données dans le cache d’un processeur vers les autres.
- Limites de ces systèmes = taille de la mémoire et nombre de CPUs disponibles.(correspond à un parallélisme sur un seul noeud).
- Cohérence de cache t0 : P1 Read X Cache P1= X=5 t1 : P2 Read X Cache P2= X=5 t2 : P1 : X=X+3 =8 t3 : Diffuser X vers RAM et Cache P2 t4 : P2 Cache P2= X=8 t5 : P2 : X=X+5=13 cette gestion a un coût :
- False sharing : dégradation des performances due à la gestion de la cohérence des caches. Le false sharing est une conséquence du principe de localité (spéciale et temporelle).
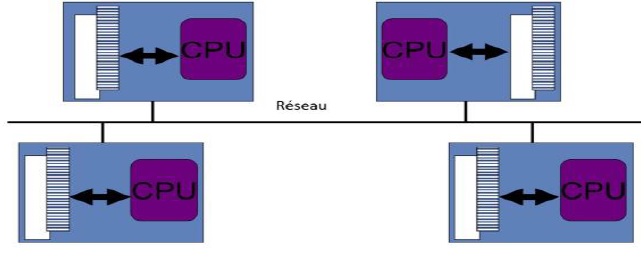
2) Systèmes à mémoire distribuée
Système multi-processeurs où la mémoire est répartie sur plusieurs noeuds.
En conséquence, chaque processeur n’a accès qu’à un sous ensemble de la mémoire.
L’accès (lecture ou écriture) à certaines parties de la mémoire nécessite des communications /échanges entre processeurs.
Le besoin d’un réseau d’interconnexion (infiniband …) pour communiquer entre les mémoires des différents processeurs.
NB : InfiniBand (IB) est une norme de communication de réseau informatique utilisée dans le calcul haute performance(HPC) qui présente un débit très élevé et une très faible latence.
Accélérateurs : chargement d’une partie du programme sur un support (co-processeur, device) spécialisé, capable de traiter plus efficacement la partie ciblée.
On parlera d”’offloading” entre le CPU (host) et l’accélérateur (device).
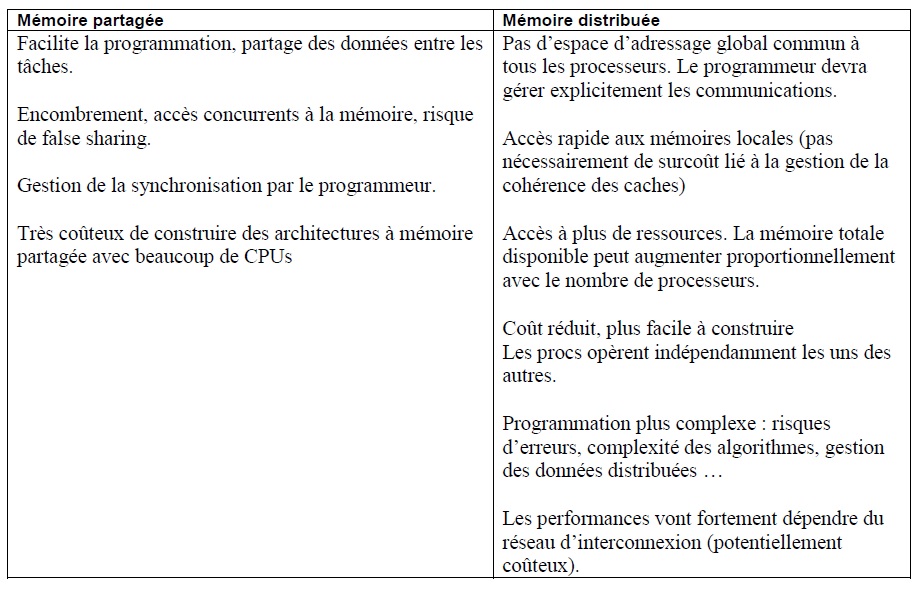
Comparaison
Exemple :
Une machine de L’IDRIS (Institut du développement et des ressources en informatique scientifique),
Machine dite convergée : noeuds hybrides CPU – GPU ; A la fois pour le HPC et le Deep Learning
Performance crête : 14 PFLop/s ; 61120 coeurs CPU, 1044 GPU.
NB : Le coût de la consommation énergétique est maintenant du même ordre que celui de l’achat de matériel.
Les modèles de programmation parallèle<
A chaque type d’architecture parallèle correspondent un ou plusieurs paradigmes de programmation, avec les langages associés.
Les modèles de programmation parallèle suivants sont les plus importants car ils ont été implémentés par des API modernes:
1) Mémoire partagée (Shared memory) : Intra-noeud , modèle à mémoire partagée, les threads peuvent lire et écrire de manière asynchrone dans une mémoire commune, utilisé pour les solutions multicoeurs
et basées sur GPU ; APIs : OpenMP : Interface Open MultiProcessing pour CPU OpenCL(Open Computing Language) et CUDA pour GPU.
Avantages
- Programmation plus facile, pas à pas.
-Espace d’adressage global, mémoires rapides, synchronisations à gérer dans le programme.
-Limites : augmentation du nombre de CPUs sur un noeud : encombrement des accès à la mémoire.
2) Passage de message (Message passing) :
Inter-noeuds, systèmes à mémoire distribuée, dans ce modèle de programmation (passage de message) ou modèle distribué, les processeurs communiquent de manière asynchrone ou synchrone en envoyant et en recevant
des messages contenant des mots de données ; MPI (Message Passing Interface) pour CPU et GPU.
-Accès à plus de ressources : il suffit d’ajouter des noeuds.
-Points critiques : les communications, la distribution des données.