HPC- High Performance Computing
Introduction
Le HPC est une technologie qui utilise des clusters de processeurs puissants, fonctionnant en parallèle,
pour traiter des ensembles de données multidimensionnels massifs (big data) et résoudre des problèmes complexes à des vitesses extrêmement élevées.
Pendant des décennies, le paradigme du système HPC était le supercalculateur, un ordinateur spécialement conçu
qui regroupe des millions de processeurs ou de coeurs de processeur.
Par exemple le supercalculateur Frontier ( États-Unis le plus rapide en 2022, 8 730 112 coeurs selon https://www.top500.org Il faut 6 000 gallons(3.78L ou 4.54 L-1m3=1000L)
d’eau pour refroidir ce supercalculateur), avec une vitesse de traitement de 1,102 exaflops.
Mais aujourd'hui, de plus en plus d'organisations exécutent des solutions HPC sur des clusters de serveurs informatiques à haut débit, hébergés sur site ou dans le cloud.
Fonctionnement du HPC Le HPC exploite :
1) Le Calcul massivement parallèle : Le calcul massivement parallèle est un calcul parallèle utilisant des dizaines de milliers,
voire des millions de processeurs ou de coeurs de processeur.
2) Clusters informatiques (également appelés clusters HPC) : Un cluster HPC se compose de plusieurs serveurs informatiques à haute vitesse mis en réseau,
avec un planificateur centralisé qui gère la charge de travail informatique parallèle.
Les ordinateurs, appelés noeuds, utilisent soit des processeurs multicoeurs hautes performances, soit, plus probablement aujourd'hui,
des GPU (unités de traitement graphique), bien adaptés aux calculs mathématiques rigoureux, aux modèles d'apprentissage automatique et aux tâches gourmandes en graphiques.
Un seul cluster HPC peut inclure 100 000 noeuds ou plus.
3) Composants hautes performances : toutes les autres ressources informatiques d'un cluster HPC (réseau, mémoire, stockage et systèmes de fichiers)
sont des composants à haute vitesse, à haut débit et à faible latence qui peuvent suivre le rythme des noeuds et optimiser la puissance de calcul et performances du cluster.
HPC et cloud computing
1- Introduction Il y a à peine dix ans, le coût élevé
du HPC (qui impliquait la possession ou la location d'un supercalculateur ou la construction et l'hébergement d'un cluster HPC dans un centre de données sur site)
mettait le HPC hors de portée pour la plupart des organisations. Aujourd'hui, le HPC dans le cloud, parfois appelé HPC en tant que service ou HPCaaS,
offre aux entreprises un moyen nettement plus rapide, plus évolutif et plus abordable pour tirer parti du HPC.
HPCaaS comprend généralement l'accès aux clusters et à l'infrastructure HPC hébergés dans le centre de données d'un fournisseur de services cloud,
ainsi que des capacités d'écosystème (telles que l'IA et l'analyse de données).
Facteurs favorisant le HPCaaS
1)Demande croissante : Les organisations de tous les secteurs dépendent de plus en plus des informations en temps réel et de l’avantage concurrentiel résultant
de la résolution de problèmes complexes que seules les applications HPC peuvent résoudre.
Par exemple, la détection des fraudes par carte de crédit...
2)Emergence de RDMA —Remote Direct Memory Access— hautes performances : RDMA permet à un ordinateur en réseau d’accéder à la mémoire
d’un autre ordinateur en réseau sans impliquer le système d’exploitation de l’un ou l’autre ordinateur ni interrompre le traitement
de l’un ou l’autre ordinateur ce qui rende possible le HPC basé sur le cloud.
3)Disponibilité du HPCaaS dans les cloud publics et privés
GPGPU- General-Purpose Graphics Processing Unit
Définition:
Une unité de traitement graphique à usage général (GPGPU) est une unité de traitement graphique (GPU) programmée à des fins allant au-delà du traitement graphique,
comme l'exécution de calculs généralement effectués par une unité centrale de traitement (CPU).
GPGPU exploite la puissance de calcul des GPUs pour le traitement des tâches massivement parallèles.
Pour cela, Nvidia développe depuis 2007 une interface matérielle et un langage de programmation dérivés du C,
CUDA (Compute Unified Device Architecture).
Tableau 1 : Comparaison entre CPU/GPU (2011)
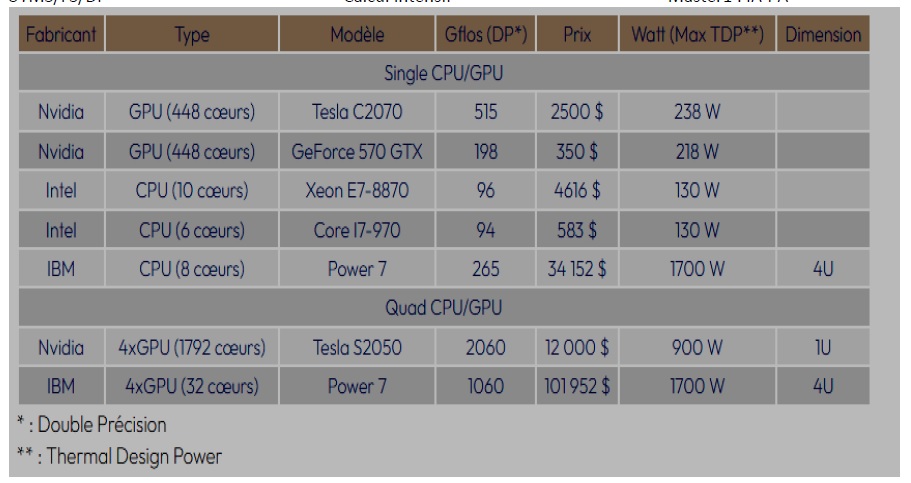
1U : une unité de rack de hauteur= 1,75 ‘’ pouces (44,45 mm) de hauteur de rack(une armoire).
GPGPU améliore l'architecture du processeur en accélérant certaines parties d'une application tandis que le reste continue de s'exécuter sur le processeur,
créant ainsi une application globalement plus rapide avec une haute performance en combinant la puissance de traitement du processeur et du GPU.
Un GPU est un processeur programmable sur lequel des milliers de coeurs de traitement s'exécutent simultanément dans un parallélisme massif,
où chaque coeur se concentre sur la réalisation de calculs efficaces, facilitant le traitement et l'analyse en temps réel d'énormes ensembles de données.
GPU est un composant matériel, le GPGPU est fondamentalement un concept logiciel dans lequel des conceptions de programmation spécialisée et d'équipement facilitent
le traitement parallèle massif de calculs non destinés au GPU. Tous les GPU modernes sont des GPGPU.
L’accélération GPGPU
L'accélération GPGPU fait référence à une méthode de calcul accéléré dans laquelle les parties à forte intensité de calcul d'une application sont attribuées au GPU
et le calcul à usage général est affecté au CPU, offrant ainsi un haut niveau de parallélisme. Alors que des calculs très complexes sont effectués dans le GPU,
des calculs séquentiels peuvent être effectués en parallèle avec le CPU.
Comment utiliser GPGPU
Ecrire une application pour GPU nécessite une plate-forme informatique parallèle et une interface de programmation d'applications (API)
qui permettent aux développeurs de logiciels et aux ingénieurs logiciels de créer des algorithmes pour modifier leur application et mapper les noyaux(Kernels)
à forte intensité de calcul sur le GPU.
GPGPU prend en charge plusieurs types de mémoire dans une hiérarchie de mémoire permettant aux concepteurs d'optimiser leurs programmes.
Exemple : Une base de données GPU utilise la puissance de calcul du GPU pour analyser d'énormes quantités de données et renvoyer des résultats en quelques millisecondes.
3-4 GPGPU dans CUDA
La plateforme CUDA est une couche logicielle qui donne un accès direct au jeu d'instructions virtuelles du GPU et aux éléments de calcul parallèles
pour l'exécution des noyaux de calcul. Conçu pour fonctionner avec des langages de programmation tels que C, C++ et Fortran.
Les périphériques CUDA sont généralement connectés à un processeur hôte et les processeurs hôtes sont utilisés pour la transmission de données et l'invocation du noyau pour les périphériques CUDA.