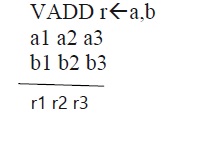Pipelining
1-1Pipelining :
Le pipeline organise l’exécution de plusieurs instructions simultanément. Le pipeline améliore le débit du système.
Dans le pipeline, l’instruction est divisée en sous-tâches.
Chaque sous-tâche exécute la tâche dédiée. Par exemple, prenons une usine de fabrication automobile.
Les taches : T0 : La préparation du châssis de l'automobile
T1 : L’ajout de la carrosserie au châssis
T2 : Le montage du moteur
T3 : Les travaux de peinture
T4 : La validation Supposant qu’on a un seul groupe qui effectue les différentes taches :
Supposant qu’on a un seul groupe qui effectue les différentes taches :

Avec le concept de pipelining : nous pouvons organiser l’assemblage de multiple voitures simultanément :
Dans ce cas on a besoin de 5 groupes d’employés ou chaque groupe effectue une tache
par exemple :
G1 : T0 ; G2 :T1 ; G3 :T2 ; G4 :T3 ; G5 :T4 ;

On observe que la sortie d’un groupe est l’entrée du groupe suivant.
Pour le calcul une instruction est devisée en cinq sous tache :
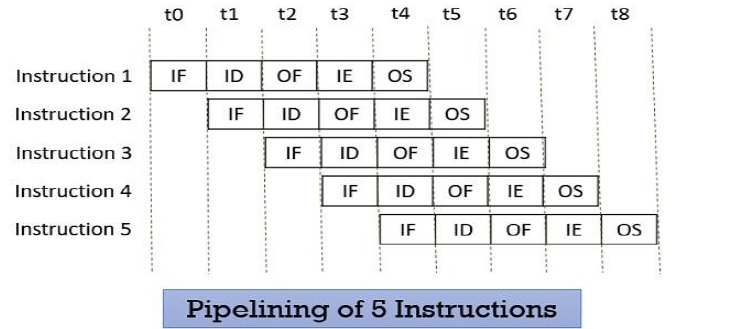
De cette façon, le matériel ne reste jamais inactif, il est toujours occupé à effectuer telle ou telle opération.
Mais deux instructions ne peuvent pas exécuter la même étape au même cycle d’horloge.
1-2 Types de pipelining
1- Pipeline arithmétique : Il est conçu pour effectuer des additions, des multiplications et des divisions à virgule flottante à grande vitesse.
Ici, multiples unités arithmétiques et logiques sont intégrées au système pour effectuer le calcul arithmétique parallèle dans différents formats de données.
Des exemples de processeurs arithmétiques pipeline sont Star-100, TI-ASC, Cray-1,
1-Cyber-205.
2- Pipeline d’instructions : Ici, les d'instructions sont en pipeline et l'exécution de l'instruction en cours est chevauchée par l'exécution de l'instruction suivante.
3- Pipeline du processeur : Ici, les processeurs sont en pipelines pour traiter le même flux de données.
Le flux de données est traité par le premier processeur et le résultat est stocké dans le bloc mémoire.
Le résultat dans le bloc mémoire est accédé par le deuxième processeur.
Le deuxième processeur retraite le résultat obtenu par le premier processeur et transmet le résultat affiné au troisième processeur et ainsi de suite.
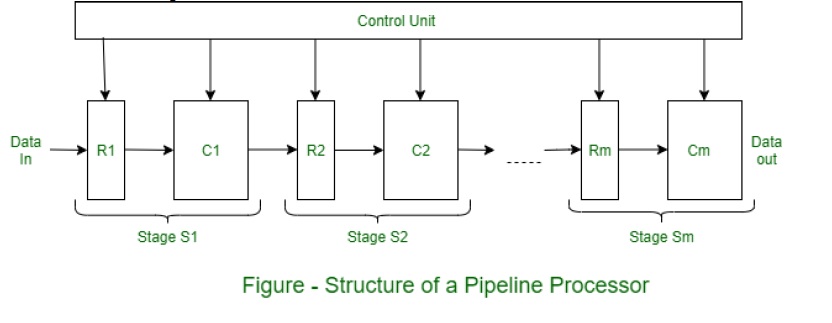
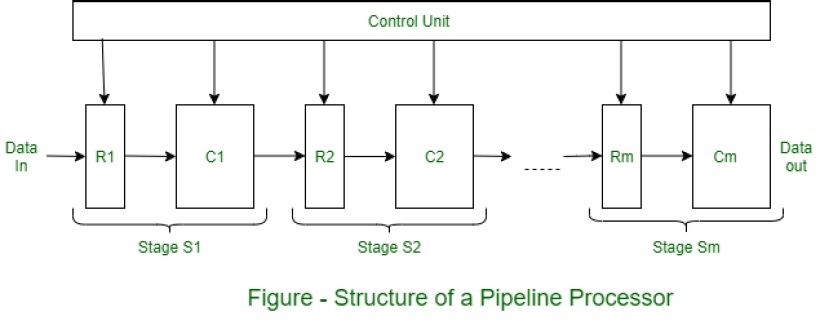
4- Unifonction vs. Pipeline multifonction :
Le pipeline qui remplit une fonction précise à chaque fois est un pipeline unifonctionnel.
D'un autre côté, le pipeline exécutant plusieurs fonctions dans différents temps ou plusieurs fonctions en même temps est un pipeline multifonction.
5- Pipelining scalaire ou vectoriel :
Le pipeline scalaire traite les instructions avec des opérandes scalaires.
Le pipeline vectoriel traite l'instruction avec des opérandes vectoriels.
1-3 Problèmes liés aux pipelines :
Ci-dessous, nous avons discuté les quatre problèmes liés au pipeline.
1- Dépendance des données : Considérez les deux instructions suivantes et leur exécution en pipeline :

Dans la figure ci-dessus, vous pouvez voir que le résultat de l'instruction Add est stocké dans le registre R2
et on sait que le résultat final est stocké à la fin de l'exécution de l'instruction qui aura lieu au cycle d'horloge t4.
Mais l'instruction Sub a besoin de la valeur du registre R2 au cycle t3.
L'instruction Sub doit donc bloquer deux cycles d'horloge. Si ce n’est pas le cas, cela générera un résultat incorrect.
Cette dépendance de données entre les instructions est appelée « dépendance de données ».
Lorsqu’une instruction ou une donnée est requise, elle est d'abord recherchée dans la mémoire cache si elle n'est pas trouvée,
il s'agit alors d'un échec de cache. Les données sont ensuite recherchées dans la mémoire, ce qui peut prendre dix cycles ou plus,
ce qui constitue un problème de retard de mémoire. Le manque de cache entraîne également le retard de toutes les instructions ultérieures.
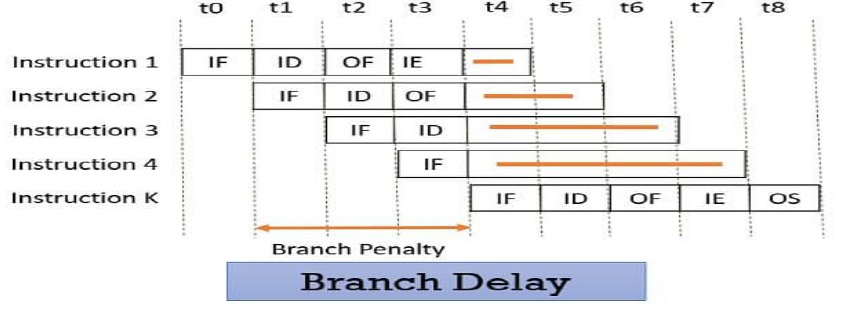
3-Retard de branchement :
Supposons que les quatre instructions soient pipeline I1, I2, I3, I4 dans une séquence.
L'instruction I1 est une instruction de branchement et son instruction cible est Ik.
Maintenant, le traitement démarre et l'instruction I1 est récupérée, décodée et l'adresse cible est calculée au 4ème étape du cycle t3.
Mais d'ici là, les instructions I2, I3, I4 sont récupérées dans les cycles 1, 2 et 3 avant que l'adresse de branche cible ne soit calculée.
Comme I1 s'avère être une instruction de branchement, les instructions I2, I3, I4 doivent être écartées car l'instruction Ik doit être traitée à côté de I1.
Ainsi, ce retard de trois cycles 1, 2, 3 est un retard de branchement.
4- Limitation des ressources
Si les deux instructions demandent à accéder à la même ressource dans le même cycle d'horloge,
alors l'une des instructions doit être bloquer et laisser l'autre instruction utiliser la ressource.
Ce blocage est dû à la limitation des ressources. Cependant, cela peut être évité en ajoutant davantage de matériel.
1-4 Avantages
1-Le pipeline améliore le débit du système.
2-Autoriser l'exécution simultanée de plusieurs instructions.
Types de parallélisme
2-1-Parallélisme au niveau de l'instruction(ILP)
Le processeur, en fonction de son jeu d’instructions, est capable d’appliquer la même instruction simultanément à plusieurs données.

Streaming SIMD Extensions, généralement abrégé SSE : est un jeu d'instructions pour microprocesseurs x86,
Le fonctionnement est de type SIMD et ajoute 70 instructions-machine supplémentaires en plus huit nouveaux registres 128 bits nommés XMM0 à XMM7.
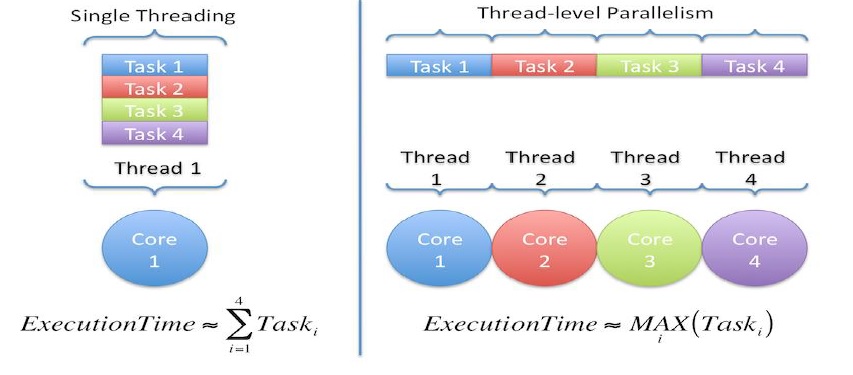
2-2 Parallélisme au niveau Thread (TLP)
Implique l'exécution simultanée de threads (tâches individuels) délégués au processeur.
Chaque thread conserve sa propre pile de mémoire et ses propres instructions, de sorte qu'il peut être considéré comme une tâche indépendante,
même si en réalité le thread n'est pas vraiment indépendant dans le programme ou le système d'exploitation.
Si les threads sont indépendants, la répartition d'un ensemble de threads parmi les coeurs
disponibles sur un processeur réduirait le temps d'exécution écoulé au temps d'exécution
maximum de l'un des threads, par rapport à une version à thread unique qui nécessiterait un
temps d'exécution supplémentaire de tous les threads
2-3 Parallélisme au niveau donnés (DLP)
Le parallélisme des données fait référence aux scénarios dans lesquels la même opération est
exécutée de manière simultanée (autrement dit, en parallèle) sur les éléments d’un tableau ou d’une collection source.