Intelligence Artificielle et le calcul parallèle
• IA désigne les dispositifs imitant ou remplaçant l'humain dans certaines mises en oeuvre de ses fonctions cognitives.
• Ce types de méthodes de résolution sont de nature complexes, que ce soit en temps de calcul ou en capacité de stockage.
• Le besoin du calcul parallèle est ainsi évident pour les applications de l’intelligence artérielle.
• Comment ?
• Par décomposition du problème en plusieurs sous problèmes plus “petits”.
Type de parallélisme
1- Data parallelism (“fine grain”) : découper/ distribuer les données.
– PD est un problème de Data parallelism si D est composé d'éléments de données et que la résolution du problème nécessite d'appliquer une fonction noyau f (…) à l'ensemble du domaine : f (D)= f (d1)+ f (d2)+···+ f (dk)
2- Task parallelism (“coarse grain”) : identifier des tâches indépendantes.
– plusieurs tâches ou sous-problèmes plus ou moins autonomes qui pourront être traités simultanément, de manière asynchrone.
– PD est un problème de tâches parallèles(Task parallelism ) si D est composé de fonctions et que la résolution du problème nécessite d'appliquer chaque fonction à un flux commun de données S. D(S)=d1(S)+d2(S)+···+dk(S).
Pour quoi le parallélisme ?
Améliorer les performances
– Obtenir une solution au problème plus rapidement.
– Résoudre des problèmes (beaucoup) plus grands .
– Traiter des volumes de données plus importants.
• Exploiter les ressources
– Mutualiser, partager les ressources.
Les défis
Un prix à payer en terme de développements:
– Conception du logiciel à revoir (probablement).
– Adaptation nécessaire des algorithmes et des méthodes utilisées.
– Apprentissage de nouveaux langages, outils (debug …).
• Utilisation/exploitation plus complexe.
• Très dépendant des architectures : il faudra les connaître, avoir une idée de leur évolution etc.
En conséquence, avant de pouvoir paralléliser il sera nécessaire de :
– Comprendre et connaître l’architecture des ressources disponibles, pour les choisir correctement et les exploiter pleinement.
– Comprendre le comportement du programme , des algorithmes, pour pouvoir l’adapter, choisir les bonnes méthodes (potentiellement différentes de celles utilisées en séquentiel).
– Connaître les modèles de programmation parallèle.
Architectures
• Les architectures informatiques définissent la manière dont les processeurs fonctionnent, communiquent et comment la mémoire est organisée ; le tout dans le contexte d’un ordinateur entièrement fonctionnel (remarque : un ordinateur fonctionnel est une implémentation d’une architecture).
• L’objectif final d’une architecture informatique est de permettre à un ordinateur d’exécuter des programmes de manière efficace et aussi rapide que possible.
• Aujourd’hui, les architectures informatiques ont évolué vers des machines parallèles car la vitesse d’horloge d’un seul coeur a atteint sa limite en fréquence.
Classification de flynn
Si tous les systèmes distribués sont formés de nombreuses UC, il existe diverses façons pour ces UC d’être connectées et de communiquer.
De nombreuses classifications des systèmes d’ordinateurs à plusieurs UC ont été proposées.
La taxonomie la plus fréquemment citée est celle de Flynn Flynn se base sur deux caractéristiques :
- le nombre des flux d’instructions
- et le nombre des flux de données.
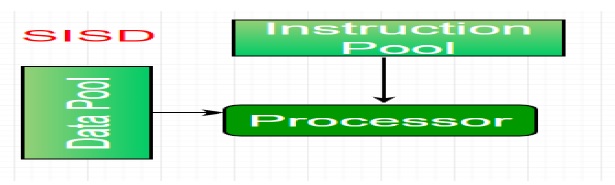
* Un ordinateur avec un seul flux d’instruction et un seul flux de données est appelé SISD (single instruction single Data).
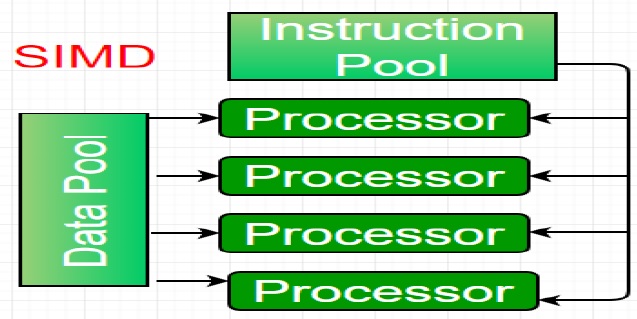
* La catégorie suivante s’appelle SIMD (single instruction multiple Data), elle se caractérise par un flux unique d’instruction et de multiple flux de données.
Ces ordinateurs sont utiles lorsqu’il faut exécuter un même calcul sur plusieurs données différentes.
Les machines basées sur un modèle SIMD sont bien adaptées au calcul scientifique
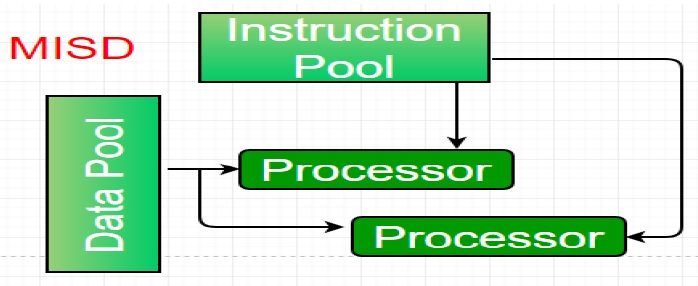
* La troisième catégorie s’appelle MISD (Multiple Instruction, Single Data),
elle est caractérisée par de multiples flots d’instructions et un seul flot de données.
* La dernière catégorie est appelée MIMD (Multiple Instructions, Multiple Data),
elle est caractérisée par un ensemble d’ordinateurs indépendants où chacun a son propre compteur ordinal,
son propre programme et ses propres données.
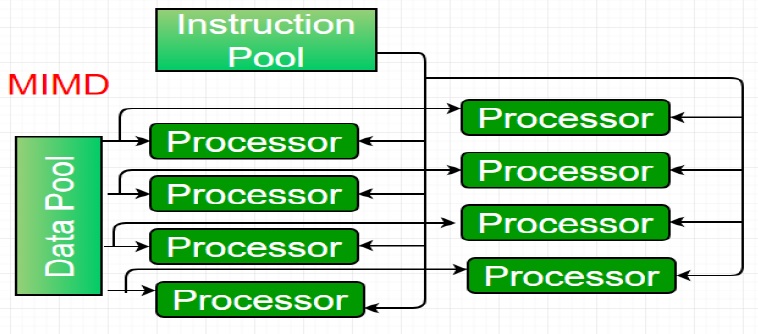
- Ces machines sont divisés en deux catégories, - ceux qui possèdent une mémoire partagée (Shared Memory (SM)), appelés multiprocesseurs. - et ceux qui non ont pas, mémoire distribuée (Distributed Memory (DM)) appelés multicalculateurs
- En couplant les critères de classification précédemment évoqués, il en résulte quatre classes différentes d’architectures parallèles :
(SIMD-SM), (SIMD-DM), (MIMD-SM), (MIMD-DM)